大模型与数据治理
专注于大规模语言模型的开发和优化,研究数据治理技术以确保数据的准确性、安全性和可用性。
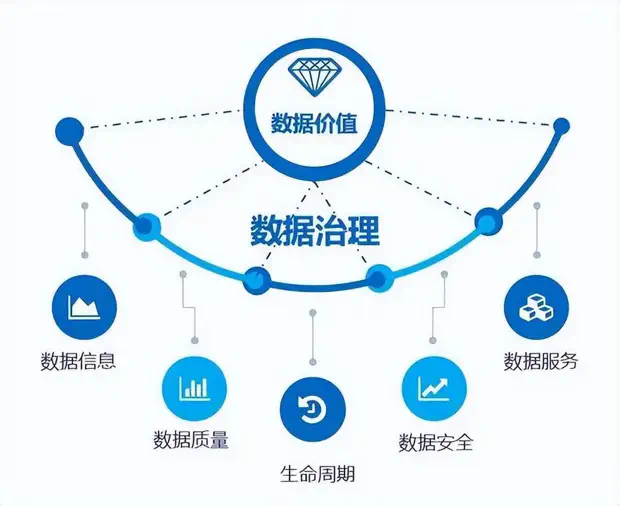
在数字化时代,数据已成为推动创新和决策的重要资产。然而,随着数据量的急剧增长和多样化,如何有效地管理和治理这些数据成为了一项紧迫的挑战。特别是在大模型的发展背景下,数据的质量和治理直接影响到模型的训练效果和应用性能。我们致力于推动数据在人工智能应用中的负责任和高效使用,最终实现数据价值变现。
研究领域
- 数据清洗技术
- 安全可信的大模型构建
- 表格数据表征
- ……
团队成员
- 何莹
- 胡哲诚
- 周煜博
- 杨彧骁
- 袁盛
- 谢畅
加入我们,一起探索数据治理的未来!